
TLDR
- 2026년 4월, Meta가 Ads MCP Server와 Ads CLI를 동시 출시했다. 같은 달 Anthropic은 Claude Code Routines와 Managed Agents를 내놓았다. 이 네 가지 도구를 조합하면 크리에이티브 피로도 관리를 완전 자율 에이전트로 구현할 수 있다
- MCP = 읽기(감지), CLI = 쓰기(대응), Claude Code Routines = 스케줄링(자동 실행) — 매일 새벽 에이전트가 스스로 깨어나 피로 소재를 스캔하고, 단계별 대응을 실행하고, Slack에 결과를 보고한다
- Frequency 3.0 이상 + CTR 주간 20% 이상 하락 동시 발생 시 즉시 교체 — 이 규칙을 MCP
anomaly_signal로 자동 감지하고, CLImeta ads ad update --status PAUSED로 즉시 실행한다 - 이 글은 크리에이티브 테스트 운영체계와 Kill/Trim/Protect/Promote 프레임워크의 후속편이다
시리즈 위치: 1편은 "어떤 소재를 테스트할 것인가"(구조 설계), 2편은 "성과가 나쁜 소재를 언제 끌 것인가"(CPA 기반 OFF 판정)를 다뤘다. 이 3편은 Meta 공식 AI 도구(MCP + CLI)를 활용해 피로도 감지 → 예측 → 대응을 에이전틱하게 자동화하는 시스템을 다룬다. 2편의 Kill 판정이 "이미 나빠진 소재를 끄는" 사후 조치라면, 3편은 "아직 CPA가 안 올랐지만 곧 올라갈 소재를 AI 에이전트가 미리 잡는" 사전 조치다.
왜 지금 "에이전틱" 피로도 관리인가
2026년 4월, 에이전틱 광고 운영에 필요한 퍼즐 조각이 한꺼번에 맞춰졌다:
- Meta Ads MCP Server (4/29) — Claude, Cursor 등 AI 에이전트가 광고 데이터를 직접 조회·분석하는 Model Context Protocol 서버
- Meta Ads CLI (4/29) — 터미널에서
meta ads <resource> <action>패턴으로 캠페인 전체 라이프사이클을 CRUD하는 커맨드라인 도구 - Claude Code Routines (4/14) — 프롬프트 + 리포 + 커넥터를 한 번 설정하면 스케줄/API/webhook으로 자동 실행되는 Claude Code 자동화. 노트북 꺼도 클라우드에서 실행된다
- Claude Managed Agents (4월 베타) — 장시간 자율 실행이 가능한 관리형 에이전트 인프라. MCP 서버 연결, bash 실행, 파일 I/O를 컨테이너 안에서 수행
이전까지 피로도 자동화는 Graph API 코드를 직접 작성하는 것이 유일한 방법이었다. Node.js로 인사이트를 수집하고, 스코어를 계산하고, 예산을 조정하는 코드를 모두 직접 짜야 했다. 이제 MCP가 읽기를, CLI가 쓰기를, Claude Routines가 스케줄링을 담당하면서, AI 에이전트가 중간에서 판단을 내리는 완전 자율 구조가 가능해졌다.
| 레이어 | 2024년식 (Graph API) | 2026년식 (MCP + CLI) |
|---|---|---|
| 데이터 수집 | Node.js fetch 코드 직접 작성 | MCP ads_get_ad_entities 호출 |
| 이상 패턴 감지 | 커스텀 스코어링 로직 | MCP ads_insights_anomaly_signal |
| 추세 분석 | rolling 평균 직접 계산 | MCP ads_insights_performance_trend |
| 벤치마크 비교 | 외부 데이터 수동 조합 | MCP ads_insights_industry_benchmark |
| 소재 OFF/ON | Graph API POST 직접 호출 | CLI meta ads ad update --status PAUSED |
| 예산 조정 | ad set PATCH 코드 | CLI meta ads adset update --daily-budget |
| 소재 교체 | creative create + ad create 코드 | CLI meta ads creative create + meta ads ad create |
| 스케줄 실행 | cron + PM2 + 자체 서버 유지 | Claude Code Routines (클라우드, 노트북 불필요) |
| 장시간 자율 실행 | 없음 (수동 트리거) | Claude Managed Agents (컨테이너 기반 세션) |
핵심 전환: "개발자가 코드를 짜서 자동화" → "AI 에이전트가 MCP로 읽고, 판단하고, CLI로 실행하고, Routines로 매일 자동 깨어남". 보일러플레이트와 인프라 운영이 사라지고 판단 로직에 집중할 수 있다.
이 글은 누구를 위한가
- 메타 광고 소재를 주 단위로 교체하면서 "언제 끄는 게 맞는지" 감에 의존하는 퍼포먼스 마케터
- CTR이 서서히 빠지는데 원인을 빈도 때문인지, 소재 자체 문제인지 구분하지 못하는 운영자
- Claude, Cursor, Windsurf 등 AI 코딩 에이전트를 업무에 쓰고 있지만, 광고 자동화까지는 연결하지 못한 팀
- 월 광고비 1,000만 원 이상 집행하면서 수동 모니터링의 한계를 느끼는 마케터
배경: 크리에이티브 피로도란
크리에이티브 피로도(Creative Fatigue)란 동일한 광고 소재가 동일한 타겟에게 반복 노출되면서 반응률이 체계적으로 하락하는 현상이다. Meta 공식 문서에서는 이를 "광고가 반복적으로 같은 사람에게 도달하여 효과가 감소하는 것"으로 정의한다(Meta 광고 관리자의 크리에이티브 피로도 가이드).
문제는 피로도가 선형적으로 악화되지 않는다는 점이다. 초기에는 미세한 CTR 하락(1~2%)으로 시작하지만, 특정 임계점을 넘으면 가속도적으로 악화된다.
피로도 악화 단계
| 단계 | Frequency | CTR 변화 | CPM 변화 | CPA 변화 | 상태 |
|---|---|---|---|---|---|
| 1. 정상 | 1.0~2.0 | 기준선 | 기준선 | 기준선 | 학습 완료, 안정 |
| 2. 초기 피로 | 2.0~3.0 | -5~15% | +5~10% | +10~20% | 주의 관찰 |
| 3. 가속 피로 | 3.0~5.0 | -20~40% | +15~30% | +30~60% | 즉시 교체 |
| 4. 심각 피로 | 5.0+ | -50%+ | +30%+ | +100%+ | 예산 낭비 |
위 수치 범위는 월 1,000만~5,000만 원 규모 Meta 캠페인 운영 경험에서 관찰된 패턴이다 (우리 팀 관측 — 업종·예산·타겟 규모에 따라 편차 존재).
수동 모니터링에 의존하면 보통 3단계(가속 피로)에 진입한 뒤에야 "성과가 떨어진다"고 인지한다. 이때 이미 2주치 예산의 상당 부분이 비효율적으로 소진된 상태다.
3단계 에이전틱 피로도 대응 프레임워크
Step 1. 감지 — MCP로 "지금 피로한가?" 자동 스캔
피로도 감지의 핵심은 단일 지표가 아닌 복합 신호를 읽는 것이다. MCP 서버의 도구들이 이 복합 판단을 네이티브로 지원한다.
감지에 사용하는 MCP 도구
| MCP 도구 | 무엇을 하는가 | 피로도 감지에서의 역할 |
|---|---|---|
ads_insights_anomaly_signal |
CTR/CPM/CPA 이상 패턴 자동 탐지 | 계정 전체를 스캔, 비정상 소재를 1차 필터링 |
ads_get_ad_entities |
ad 레벨 frequency, ctr, cpm을 필터·정렬 조회 | 1차 필터링된 소재의 Frequency × CTR 교차 검증 |
ads_insights_performance_trend |
CTR, CPM, CPC 시계열 추이 분석 | 주간 rolling 하락률 자동 계산 |
ads_insights_industry_benchmark |
동종 업계 벤치마크 비교 | 시즌 효과 vs 피로 구분 (오탐 방지) |
ads_insights_auction_ranking_benchmarks |
경매 경쟁력 + 소재 품질 진단 | 피로 원인이 소재인지 경쟁 환경인지 구분 |
에이전트 워크플로우: 3단계 감지
Step 1-1. 계정 전체 이상 스캔
AI 에이전트가 MCP ads_insights_anomaly_signal을 호출한다. 이 도구는 계정 내 모든 활성 소재를 스캔해서 CTR 급락, CPM 급등 등 비정상 패턴이 있는 소재를 자동으로 탐지한다.
→ MCP: ads_insights_anomaly_signal(ad_account_id: "123456789")
← 결과: ad_id 3건에서 CTR 이상 패턴 감지
Step 1-2. 해당 소재의 Frequency × CTR 교차 검증
탐지된 소재에 대해 ads_get_ad_entities로 frequency와 ctr을 조회한다. Frequency × CTR 동시 판단이 피로도 진단의 핵심이다.
→ MCP: ads_get_ad_entities(
ad_account_id: "123456789",
level: "ad",
fields: ["id", "name", "frequency", "ctr", "cpm", "impressions", "reach"],
filtering: [{ field: "ad.frequency", operator: "GREATER_THAN", value: ["3.0"] }],
date_preset: "last_7d"
)
← 결과: frequency ≥ 3.0인 소재 목록 + 각각의 CTR
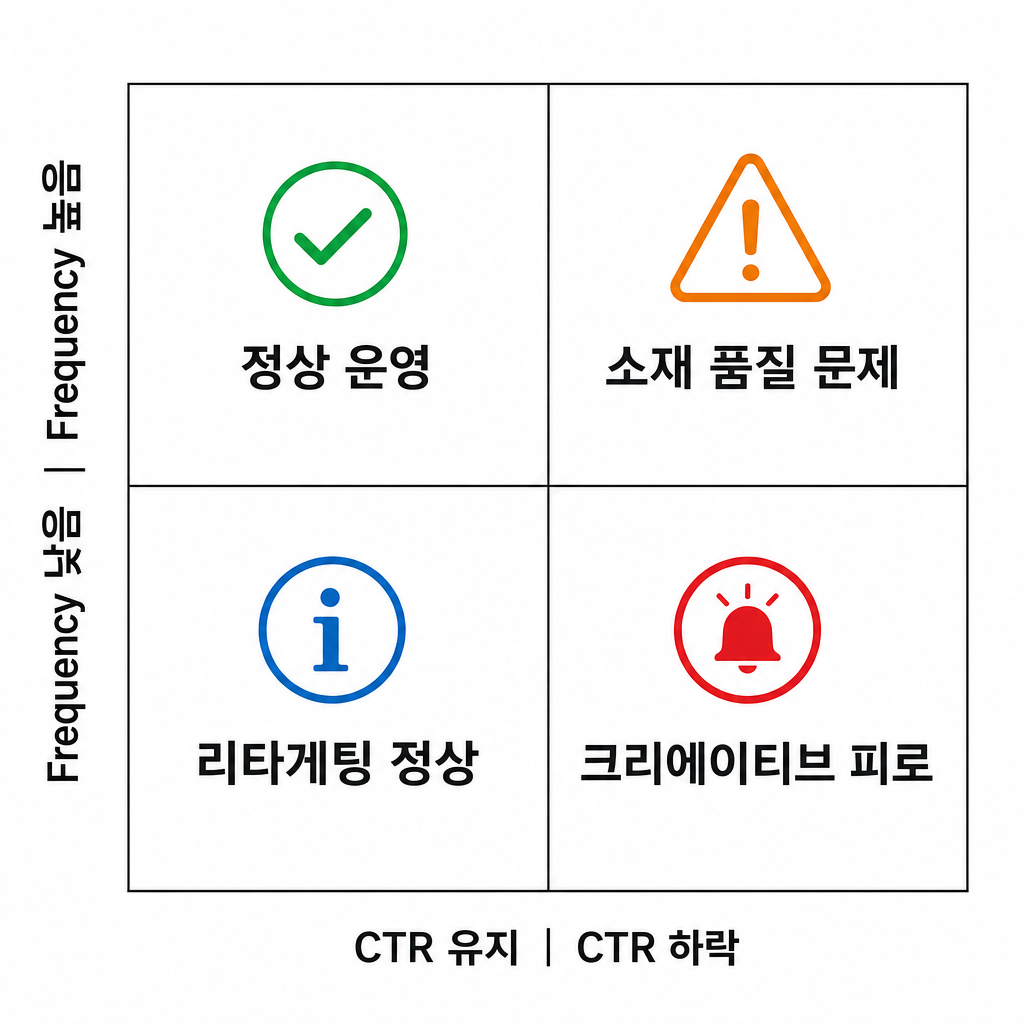
핵심 규칙: Frequency × CTR 동시 판단. Frequency가 높아도 CTR이 유지되면 피로가 아니다 — 리타게팅 캠페인에서 흔히 발생한다. 반대로 Frequency가 낮은데 CTR이 급락하면 소재 자체 문제(크리에이티브 품질)이지 피로가 아니다.
| CTR 유지 | CTR 하락 | |
|---|---|---|
| Frequency 낮음 | 정상 운영 | 소재 품질 문제 → 교체 |
| Frequency 높음 | 리타게팅 정상 | 크리에이티브 피로 → 즉시 대응 |
Step 1-3. 벤치마크 비교로 오탐 배제
CTR 하락이 피로 때문인지, 시즌 효과(연말, 명절, 경쟁 심화)인지 구분해야 한다. ads_insights_industry_benchmark로 동종 업계 평균과 비교한다.
→ MCP: ads_insights_industry_benchmark(
ad_account_id: "123456789",
analysis_metric: "CTR",
conversation_topic: "CREATIVE"
)
← 결과: 업계 평균 CTR 대비 내 소재의 상대 위치
업계 전체 CTR이 하락 중이면 시즌 효과 → 피로 판정 보류. 내 소재만 하락이면 피로 확정.
Graph API로 같은 것을 하려면: Node.js로 insights API 호출 코드, rolling 평균 계산 로직, 벤치마크 외부 데이터 조합까지 약 200줄의 보일러플레이트가 필요했다. MCP는 이 3단계를 도구 3번 호출로 대체한다.
Step 2. 예측 — "언제 피로해질 것인가?"
감지보다 한 단계 발전한 접근은 피로 시점을 예측하는 것이다. 이 단계는 MCP/CLI로 대체되지 않는 영역이다 — 과거 소재 수명 데이터에서 패턴을 추출하는 통계 로직이 필요하다.
예측 로직 (단순 버전)
- 과거 소재 수명 데이터 수집: MCP
ads_get_ad_entities로 지난 90일간 운영한 소재별 frequency 추이를 조회한다. "Frequency 3.0 도달까지 걸린 일수"를 기록한다 - 소재 유형별 평균 수명 산출: 이미지/영상/캐러셀 등 포맷별로 평균과 표준편차를 계산한다
- 신규 소재 투입 시 예상 교체일 설정: 평균 수명의 80% 시점에 사전 알림을 설정한다
# 소재 수명 예측 (단순 통계 기반)
import statistics
def predict_fatigue_date(historical_lifespans_days: list[int]) -> dict:
"""과거 소재 수명 데이터로 다음 소재의 예상 피로 시점을 예측한다."""
avg = statistics.mean(historical_lifespans_days)
std = statistics.stdev(historical_lifespans_days) if len(historical_lifespans_days) > 1 else 0
return {
"avg_lifespan_days": round(avg, 1),
"std_days": round(std, 1),
"early_warning_day": round(avg * 0.8), # 80% 시점 사전 경고
"hard_deadline_day": round(avg * 1.0), # 평균 수명 도달
"confidence": "high" if std / avg < 0.3 else "medium" if std / avg < 0.5 else "low"
}
# 예시: 지난 90일간 이미지 소재 10개의 수명
image_lifespans = [12, 15, 11, 18, 14, 13, 16, 10, 14, 17]
prediction = predict_fatigue_date(image_lifespans)
# → avg_lifespan_days: 14.0, early_warning_day: 11, confidence: "high"
예측 정확도가 높을수록 소재 준비 리드타임을 확보할 수 있다. 평균 수명이 14일이고 신규 소재 제작에 3~5일이 걸린다면, 투입 후 9일차에 다음 소재 제작을 시작해야 공백 없이 교체할 수 있다.
예측 정확도 backtesting: "이 예측이 실제로 맞는가?"
예측 모델은 검증 없이 쓰면 위험하다. walk-forward 방식으로 "처음 N개 소재로 예측 → 나머지 소재의 실제 수명과 비교"한다.
# Walk-forward backtesting: 예측 정확도 검증
import statistics
def backtest_predictions(lifespans: list[int], train_ratio: float = 0.6) -> dict:
"""과거 소재 수명 데이터를 train/test로 나눠 예측 정확도를 검증한다."""
n = len(lifespans)
split = int(n * train_ratio)
if split < 3 or (n - split) < 2:
return {"error": "데이터 부족 — 최소 소재 5개 이상 필요"}
train = lifespans[:split]
test = lifespans[split:]
# train set으로 예측 생성
pred_avg = statistics.mean(train)
pred_std = statistics.stdev(train)
early_warning = pred_avg * 0.8
# test set 각 소재에 대해 평가
results = []
for actual in test:
error_days = abs(actual - pred_avg)
within_1std = error_days <= pred_std
early_warning_hit = early_warning <= actual # 사전 경고가 실제 피로 전에 발동했는가
results.append({
"actual": actual,
"predicted": round(pred_avg, 1),
"error_days": round(error_days, 1),
"within_1std": within_1std,
"early_warning_useful": early_warning_hit
})
within_1std_pct = sum(1 for r in results if r["within_1std"]) / len(results) * 100
early_warning_hit_pct = sum(1 for r in results if r["early_warning_useful"]) / len(results) * 100
mae = statistics.mean([r["error_days"] for r in results])
return {
"train_size": split,
"test_size": len(test),
"predicted_avg_days": round(pred_avg, 1),
"mae_days": round(mae, 1),
"within_1std_pct": round(within_1std_pct, 1),
"early_warning_hit_pct": round(early_warning_hit_pct, 1),
"verdict": "usable" if within_1std_pct >= 60 and early_warning_hit_pct >= 80 else "needs_more_data"
}
# 예시 (시연용 가상 데이터)
all_lifespans = [12, 15, 11, 18, 14, 13, 16, 10, 14, 17, 13, 15, 11, 16, 12]
bt = backtest_predictions(all_lifespans)
# → train_size: 9, test_size: 6
# → predicted_avg_days: 13.7, mae_days: 1.8
# → within_1std_pct: 83.3%, early_warning_hit_pct: 100%
# → verdict: "usable"
판독 기준: - within_1std_pct ≥ 60%: 예측이 ±1 표준편차 안에 드는 비율. 60% 미만이면 소재 유형별로 분리해 재학습 - early_warning_hit_pct ≥ 80%: 80% 시점 사전 경고가 실제 피로 전에 발동하는 비율. 80% 미만이면 경고 시점을 70%로 당겨라 - mae_days ≤ 3: 평균 절대 오차 3일 이내면 소재 제작 리드타임 역산에 실용적
ML 모델(survival analysis, LSTM 시계열)을 적용하면 정밀도가 올라가지만, 월 집행 소재 수가 30개 이하인 팀에서는 위 통계 기반 접근 + backtesting만으로 충분하다. 핵심은 모델의 복잡도가 아니라, 예측을 검증하는 습관이다.
Step 3. 대응 — CLI로 "피로 소재를 즉시 처리"
피로 감지 후 대응은 Kill/Trim/Protect/Promote 프레임워크의 확장이다. MCP가 감지를 담당했다면, CLI가 대응을 담당한다. Meta Ads CLI는 --no-input, --force 플래그로 무인 자동화를 지원하고, JSON 출력으로 스크립트 파이핑이 가능하다.
단계별 자동 대응 매트릭스
| 피로 단계 | 자동 액션 | CLI 명령 | 수동 확인 필요 여부 |
|---|---|---|---|
| 초기 피로 (Freq 2.0~3.0) | 예산 비중 -20% 자동 조정 | meta ads adset update <ID> --daily-budget <NEW> |
아니오 — 모니터링만 |
| 가속 피로 (Freq 3.0~5.0) | Slack 알림 + 대기 소재 활성화 제안 | meta ads ad get <ID> --format json → Slack webhook |
예 — 교체 승인 |
| 심각 피로 (Freq 5.0+) | 소재 자동 OFF + 백업 소재 ON | meta ads ad update <ID> --status PAUSED --force |
아니오 — 즉시 실행 |
에이전트 대응 파이프라인
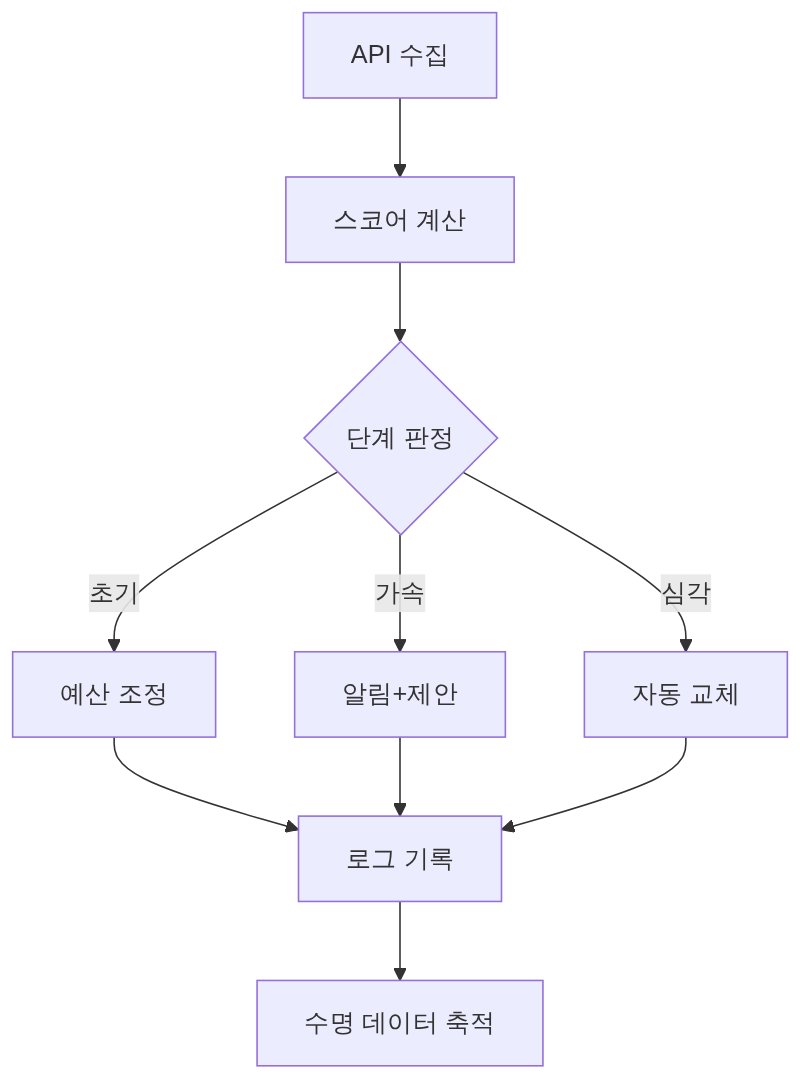
파이프라인 단계 요약: - MCP 감지 → anomaly_signal + ads_get_ad_entities로 피로 소재 탐지 - AI 판단 → Frequency × CTR 매트릭스 + 벤치마크 비교로 피로 단계 분류 - CLI 실행 → 단계별 대응 — 예산 조정, 소재 OFF, 백업 소재 ON - 로그 축적 → 모든 대응 결과 저장, 수명 데이터로 예측 정밀도 향상
대응 자동화 스크립트 (CLI + MCP 조합)
아래 스크립트는 MCP로 감지한 피로 소재 목록을 받아, CLI로 단계별 대응을 자동 실행한다. cron으로 매일 09:00에 실행한다.
#!/bin/bash
# fatigue-response.sh — MCP 감지 결과를 받아 CLI로 자동 대응
# 사전 조건: META_AD_ACCOUNT_ID, META_ACCESS_TOKEN, SLACK_WEBHOOK_URL 환경변수 설정
set -euo pipefail
ACCOUNT_ID="${META_AD_ACCOUNT_ID}"
LOG_FILE="fatigue-actions-$(date +%Y%m%d).jsonl"
# ── 1. CLI로 피로 후보 소재 조회 (frequency ≥ 3.0인 활성 소재) ──
echo "[$(date -Iseconds)] Scanning fatigued ads..." >&2
FATIGUED_ADS=$(meta ads ad list \
--account-id "$ACCOUNT_ID" \
--fields id,name,frequency,ctr,cpm,status \
--format json \
--no-input 2>/dev/null | \
jq '[.[] | select(.frequency >= 3.0 and .status == "ACTIVE")]')
COUNT=$(echo "$FATIGUED_ADS" | jq 'length')
if [ "$COUNT" -eq 0 ]; then
echo "[$(date -Iseconds)] No fatigued ads detected. Clean." >&2
exit 0
fi
echo "[$(date -Iseconds)] Found $COUNT fatigued ads." >&2
# ── 2. 단계별 대응 ──
echo "$FATIGUED_ADS" | jq -c '.[]' | while read -r ad; do
AD_ID=$(echo "$ad" | jq -r '.id')
AD_NAME=$(echo "$ad" | jq -r '.name')
FREQ=$(echo "$ad" | jq -r '.frequency')
CTR=$(echo "$ad" | jq -r '.ctr')
# 피로 단계 분류
if (( $(echo "$FREQ >= 5.0" | bc -l) )); then
STAGE="severe"
# 심각 피로: 즉시 OFF
meta ads ad update "$AD_ID" --status PAUSED --force --no-input 2>/dev/null
ACTION="PAUSED"
elif (( $(echo "$FREQ >= 3.0" | bc -l) )); then
STAGE="active"
# 가속 피로: Slack 알림 (교체 승인 대기)
ACTION="ALERT_SENT"
curl -s -X POST "$SLACK_WEBHOOK_URL" \
-H 'Content-Type: application/json' \
-d "{\"text\":\"⚠️ 피로 감지: *${AD_NAME}* (freq=${FREQ}, CTR=${CTR}) → 교체 검토 필요\"}" \
>/dev/null
fi
# 로그 기록
echo "{\"ts\":\"$(date -Iseconds)\",\"ad_id\":\"$AD_ID\",\"name\":\"$AD_NAME\",\"freq\":$FREQ,\"ctr\":$CTR,\"stage\":\"$STAGE\",\"action\":\"$ACTION\"}" >> "$LOG_FILE"
echo "[$(date -Iseconds)] $AD_NAME: $STAGE → $ACTION" >&2
done
echo "[$(date -Iseconds)] Done. Actions logged to $LOG_FILE" >&2
CLI가 Graph API 코드를 대체하는 지점:meta ads ad update <ID> --status PAUSED --force가 기존의fetch('https://graph.facebook.com/v21.0/${adId}', { method: 'POST', body: JSON.stringify({ status: 'PAUSED' }) })코드 블록 전체를 대체한다.--format json과jq조합으로 파이핑하면 별도의 파싱 코드도 불필요하다.
다음 단계: Claude Code Routines로 완전 자율화
위 bash 스크립트를 cron에 등록하는 것도 방법이지만, 2026년 4월 출시된 Claude Code Routines를 쓰면 자체 서버 없이 클라우드에서 자동 실행할 수 있다.
Routines는 프롬프트 + 리포 + 커넥터를 한 번 설정하면 스케줄(매일/매주), API 호출, 또는 GitHub webhook으로 트리거된다. 노트북을 닫아도 Claude Code 웹 인프라에서 실행된다.
피로도 감지 Routine 설정 예시:
매일 오전 9시 KST:
1. Meta Ads MCP로 계정 전체 anomaly_signal 스캔
2. frequency ≥ 3.0 + CTR 하락 소재 식별
3. industry_benchmark로 시즌 효과 오탐 배제
4. 심각 피로(freq 5.0+) → CLI로 즉시 PAUSED
5. 가속 피로(freq 3.0~5.0) → Slack 커넥터로 알림
6. 결과를 리포의 fatigue-log.jsonl에 append
cron + bash 대비 이점:
| cron + bash | Claude Code Routine | |
|---|---|---|
| 인프라 | 자체 서버/VM 필요 | 클라우드 (Anthropic 관리) |
| MCP 접근 | 별도 설정 필요 | 커넥터로 내장 연결 |
| 판단 로직 | jq + if/else 하드코딩 | AI가 컨텍스트 기반 판단 |
| 예외 처리 | 스크립트 에러 → 침묵 실패 | 에이전트가 에러 분석 후 Slack 보고 |
| 확장 | 스크립트 수정 + 재배포 | 프롬프트 수정만 |
cron 스크립트는 규칙 기반(frequency ≥ 5.0이면 OFF)으로만 동작한다. Routine은 에이전트가 "이 소재는 frequency 4.8이지만 CTR이 어제부터 급락 중이고 벤치마크 대비 하위 10%" 같은 복합 판단을 내릴 수 있다. 규칙의 경계값에서 발생하는 오탐/미탐을 줄이는 핵심 차이다.
장시간 분석이 필요한 경우(예: 90일 소재 수명 backtesting + 리포트 생성)에는 Claude Managed Agents가 적합하다. Managed Agent는 컨테이너 기반 세션에서 MCP 서버, bash, 파일 I/O를 활용해 수십 분~수 시간 자율 실행할 수 있다.
절감 효과 시뮬레이션: "자동화하면 얼마나 아끼는가?"
"자동 감지 vs 수동 감지"의 예산 차이를 Monte Carlo 시뮬레이션으로 검증한다.
# Monte Carlo 시뮬레이션: 자동 감지 vs 수동 감지 예산 낭비 비교
import random
import statistics
def simulate_fatigue_savings(
n_creatives: int = 16,
daily_budget: int = 3_000_000, # 원
target_cpa: int = 20_000,
avg_lifespan_days: int = 14,
manual_detect_lag_days: int = 10, # 수동: 피로 진입 후 감지까지 평균 지연
auto_detect_lag_days: int = 2, # 자동: 24~48시간 내 감지
cpa_multiplier_fatigued: float = 1.8, # 피로 소재의 CPA는 정상 대비 1.8×
simulations: int = 10_000
) -> dict:
"""피로 소재에 소진되는 '초과 비용'을 수동 vs 자동으로 비교한다."""
manual_waste = []
auto_waste = []
for _ in range(simulations):
lifespan = max(7, random.gauss(avg_lifespan_days, 3))
daily_share = (daily_budget / n_creatives) * random.uniform(0.5, 1.5)
normal_cpa = target_cpa
fatigued_cpa = target_cpa * cpa_multiplier_fatigued
manual_lag = max(1, random.gauss(manual_detect_lag_days, 3))
manual_excess = daily_share * manual_lag * (1 - normal_cpa / fatigued_cpa)
auto_lag = max(0.5, random.gauss(auto_detect_lag_days, 0.5))
auto_excess = daily_share * auto_lag * (1 - normal_cpa / fatigued_cpa)
manual_waste.append(manual_excess)
auto_waste.append(auto_excess)
manual_avg = statistics.mean(manual_waste)
auto_avg = statistics.mean(auto_waste)
saving_pct = (manual_avg - auto_avg) / manual_avg * 100
return {
"manual_excess_per_creative_won": round(manual_avg),
"auto_excess_per_creative_won": round(auto_avg),
"saving_per_creative_won": round(manual_avg - auto_avg),
"saving_pct": round(saving_pct, 1),
"simulations": simulations
}
result = simulate_fatigue_savings()
# 가상 시나리오 결과 예시 (시연용):
# manual_excess_per_creative_won: ~104,000
# auto_excess_per_creative_won: ~21,000
# saving_per_creative_won: ~83,000
# saving_pct: ~80% ← 피로 소재 '초과 비용'의 80% 절감
해석 주의: 위 시뮬레이션은 "피로 소재에 낭비되는 초과 비용"만 비교한 것이다. 전체 광고비 대비 절감률이 아니라, 피로 구간에서 발생하는 비효율의 80%를 자동 감지로 회수한다는 의미다. 본인 캠페인 수치로 파라미터를 바꿔 돌려보라. (시연용 — 실제 결과는 캠페인 구조에 따라 편차 존재)
소재 교체 시 주의사항
- 학습 단계 보호: 신규 소재 투입 후 최소 3~5일(또는 노출 8,000회 이상)은 피로도 판단을 보류한다. 학습 단계에서의 지표 변동은 피로가 아니다 — 크리에이티브 테스트 운영체계 참조
- 동시 교체 제한: 한 캠페인에서 소재를 50% 이상 동시 교체하면 머신러닝 재학습이 발생한다. 최대 30%씩 순차 교체를 권장한다
- 시즌 효과 구분: 연말, 명절, 세일 시즌에는 전체 CTR이 하락할 수 있다. MCP
ads_insights_industry_benchmark로 벤치마크 비교하면 피로와 시즌을 구분할 수 있다
MCP + CLI 도구 선택 가이드
"무엇을 쓸까"를 한눈에 정리한다:
| 작업 | 도구 | 이유 |
|---|---|---|
| 피로 소재 탐지 | MCP anomaly_signal |
자동 이상 패턴 감지, 코드 불필요 |
| frequency/ctr 조회 | MCP ads_get_ad_entities |
필터·정렬 내장, ad 레벨 데이터 |
| 추세 분석 | MCP performance_trend |
시계열 자동 분석 |
| 벤치마크 비교 | MCP industry_benchmark |
오탐 방지, 동종 업계 데이터 |
| 피로 수명 예측 | Python 통계 코드 | 커스텀 로직 필요, MCP/CLI 범위 밖 |
| 소재 OFF/ON | CLI meta ads ad update --status |
한 줄로 상태 변경 |
| 예산 조정 | CLI meta ads adset update --daily-budget |
ad set 레벨 예산 직접 수정 |
| 소재 교체 | CLI meta ads creative create + ad create |
새 소재 등록 + 광고 생성 |
| 스크립트 자동화 | CLI --no-input --force --format json |
cron + jq 파이핑 |
| 스케줄 자동 실행 | Claude Code Routines | 매일/매주, 클라우드, 서버 불필요 |
| 장시간 분석 | Claude Managed Agents | 90일 backtesting 등 수십 분 작업 |
Graph API는 죽었는가? 아니다. 커스텀 attribution window 계산, 대량 배치 처리(1,000+ 소재 동시 조작), webhook 기반 실시간 트리거 등 MCP/CLI가 커버하지 않는 엣지 케이스에서는 여전히 필요하다. 핵심은 기본 워크플로우를 MCP + CLI로 단순화하고, 예외적 케이스에서만 Graph API로 fallback하는 것이다.
실행 체크리스트: 내일부터 시작하기
- [ ] Meta Ads MCP Server 설정 — Claude Desktop 또는 Cursor에 MCP 서버 연결
- [ ] Meta Ads CLI 설치 —
META_AD_ACCOUNT_ID,META_ACCESS_TOKEN환경변수 설정 - [ ] MCP
ads_insights_anomaly_signal로 현재 계정의 이상 소재를 첫 스캔한다 - [ ]
ads_get_ad_entities로 Frequency ≥ 3.0이면서 CTR이 주간 -20% 이상인 소재를 식별한다 - [ ] CLI
meta ads ad list --format json으로 활성 소재 목록을 JSON으로 뽑아본다 - [ ] Claude Code Routines로 매일 09:00 자동 스캔을 설정한다 (또는 위 bash 스크립트를 cron에 등록한다). 첫 2주는 수동 검증과 병행한다
- [ ] 과거 소재의 "Frequency 3.0 도달까지 일수" 평균을 산출하고, backtesting으로 검증한다
- [ ] 소재 제작 리드타임을 역산하여 사전 제작 일정을 캘린더에 설정한다
흔한 실수와 회피 방법
| 실수 | 왜 문제인가 | 올바른 접근 |
|---|---|---|
| Frequency만 보고 교체 | 리타게팅에서는 Frequency 10+도 정상일 수 있다 | Frequency × CTR 복합 판단 (MCP 2단계 조회) |
| 모든 소재를 동시 교체 | 머신러닝 재학습으로 1~2주 성과 공백 발생 | 30%씩 순차 교체 |
| MCP 결과를 무조건 신뢰 | anomaly_signal은 관찰일 뿐, 확정 아님 | 벤치마크 + Frequency × CTR 교차 검증 필수 |
| CLI --force를 모든 단계에 적용 | 초기 피로에서 자동 OFF하면 학습 중인 소재 사망 | 심각 피로(5.0+)에서만 --force 사용 |
| 피로 감지 후 "새 소재 만들기"부터 시작 | 제작 리드타임 동안 예산 계속 낭비 | 항상 대기 소재 2~3개를 사전 준비 |
| 전환 캠페인에만 적용 | 인지도/트래픽 캠페인도 피로 발생 | 캠페인 목적 불문 적용 |
결론: AI 에이전트가 광고를 운영하는 시대
2026년 4월 Meta의 MCP + CLI 동시 출시, 그리고 Anthropic의 Claude Code Routines와 Managed Agents 베타까지 — 이 네 가지가 동시에 등장한 것은 우연이 아니다. "개발자가 코드를 짜서 자동화"에서 "AI 에이전트가 읽고, 판단하고, 실행"으로의 패러다임 전환이 본격화된 것이다.
이 글에서 제시한 에이전틱 피로도 프레임워크를 정리하면:
- 감지 (MCP):
anomaly_signal→ads_get_ad_entities→industry_benchmark로 3단계 자동 스캔. 24~48시간 내 피로 감지 (수동 대비 7~14일 단축) - 예측 (Python): 과거 수명 데이터 + walk-forward backtesting으로 피로 시점 선제 예측. MCP로 데이터 수집, Python으로 분석
- 대응 (CLI):
meta ads ad update --status PAUSED --force로 즉시 실행. 피로 초과 비용의 ~80% 회수 (Monte Carlo 시뮬레이션 기준) - 자율화 (Routines + Managed Agents): Claude Code Routines로 매일 자동 스캔을 클라우드에서 실행하고, Managed Agents로 90일 backtesting 같은 장시간 분석을 컨테이너에서 자율 수행. cron + bash 스크립트 → 자연어 Routine 한 줄로 교체
핵심은 도구의 수가 아니라 조합이다. MCP가 데이터를 읽고, CLI가 실행하고, Routines가 스케줄을 잡고, Managed Agents가 장시간 분석을 맡는다. 각 도구가 하나의 역할만 담당하는 이 구조가, 결국 사람이 개입하지 않아도 되는 완전 자율 광고 운영의 기반이 된다.
다음 단계로 시그널 엔지니어링 2.0을 함께 읽으면, 피로도 관리와 전환 시그널 최적화를 결합한 종합 전략을 세울 수 있다.
더 읽어보기
- 메타 광고 크리에이티브 테스트 운영체계: 2026 실전 가이드 — 3-3-3 프레임워크와 BAU/테스트 분리 설계
- 메타 광고 소재 OFF 기준, Kill/Trim/Protect/Promote 프레임워크 — Target CPA 기반 소재 종료 의사결정
- 시그널 엔지니어링 2.0 — 메타 광고 알고리즘을 훈련시키는 전략적 데이터 설계 — CAPI 이후의 시그널 최적화
- Agentic Commerce: 메타 광고 감사 — AI 에이전트 기반 광고 운영 자동화
참고 자료
- Meta Ads AI Connectors — Meta 공식 MCP + CLI 소개 (비즈니스 지원 센터)
- Meta Ads CLI Overview — CLI 설치, 명령어 레퍼런스, 자동화 가이드
- Meta Ads MCP Server — MCP 서버 설정 및 도구 목록
- Meta 광고 관리자의 크리에이티브 피로도 가이드 — Meta 공식 피로도 정의 및 권장 사항
- Meta Creative Fatigue and Similarity Score: Complete Guide — Admetrics — Similarity Score와 피로도 상관관계
- How to Detect Ad Creative Fatigue Before It Kills Your ROAS — Adligator — 2026 피로도 감지 체크리스트
- 광고 피로도란 무엇인가요? 진단, 예방 및 해결 방법 — Amazon Advertising — 플랫폼 불문 피로도 개념 정리
- Claude Code Routines — Anthropic — 스케줄/API/웹훅 기반 자동화, 클라우드 실행
- Claude Managed Agents — Anthropic — 장시간 자율 실행 에이전트, 컨테이너 기반 세션