
TLDR
- 메타 광고에서 "이 소재를 언제 OFF할까"는 시간 경과가 아니라 누적 지출 대비 Target CPA 배수로 판단해야 통계적으로 성립한다.
- OFF/KEEP 이진 결정 대신 Kill / Trim / Protect / Promote / Keep 5-state 라이프사이클을 쓰면 ATC·VT만 좋은 upper-funnel feeder 소재를 실수로 죽여 퍼널이 흔들리는 사고(운영 커뮤니티 용어로 creative ecosystem effect)를 예방할 수 있다.
- 하루 OFF 상한을 활성 소재의 20%로 묶는 Blast Radius 규칙과, OFF 후 남은 소재의 CTR·blended ROAS를 7일간 감시하는 Guard Mode가 "한꺼번에 너무 많이 끄다 KPI가 흔들리는" 경우의 롤백 경로를 보장한다.
- 규칙을 바꾸기 전에는 3층 게이트(Poisson 오탐률 수학 → walk-forward 시뮬레이션 → Shadow-mode 파일럿 2주)로 검증해서 피봇 리스크를 단계별로 줄인다.
1. 이 글은 누구를 위한 것인가
메타 광고(Meta Ads, 페이스북·인스타그램 광고)를 직접 운영하는 퍼포먼스 마케터, 그로스 팀장, D2C/앱 마케팅 리더를 위한 글입니다. 광고비 월 수백만 원~수억 원을 집행하면서 "이 소재를 언제 끄고 언제 살릴지"를 매일 결정해야 하는 분들 대상입니다.
다음과 같은 증상이 있다면 이 글이 직접적인 도움이 됩니다.
- 일예산을 올렸는데 ROAS(Return on Ad Spend, 광고비 대비 매출)가 몇 주째 목표의 절반 근처에서 정체
- 매니저마다 "이 소재 끄자 / 더 보자"가 갈려서 의사결정이 감(感)에 의존
- "최근 3일 전환 없음"이나 "Frequency(빈도) 4 이상" 같은 규칙을 쓰는데 효과가 애매함
- 소재를 끄고 나면 다른 소재들의 클릭률(CTR)·전환율(CVR)도 같이 떨어지는 일이 반복
이 글에서 소개하는 프레임워크는 실제 캠페인을 돌리면서 반복적으로 마주친 실패 사례들을 역산해서, Meta 공식 문서와 RevenueCat의 High-Velocity Creative Testing Framework, Jon Loomer의 메트릭 가이드 등 공개 레퍼런스를 통합해 정리한 것입니다. 가상 시나리오의 숫자는 그대로 쓰지 말고, 본인 제품의 Target CPA에서 재계산해서 적용하세요.
2. 왜 흔한 OFF 규칙은 ROAS 회복을 막는가
현장에서 자주 쓰이는 소재 OFF 규칙 세 가지를 점검해봅시다.
- "최근 3일간 전환이 없으면 OFF"
- "일예산의 5% 이상 소진했는데 ROAS 40% 미만이면 OFF"
- "Frequency(빈도) 4 이상이면 OFF"
세 규칙 모두 겉으로는 합리적입니다. 실제로는 구조적 결함이 있습니다.
결함 1. 시간은 통계적 단위가 아니다
소재 평가의 단위는 "며칠이 지났는가"가 아니라 "얼마나 많은 관측치를 받았는가"입니다. 메타 AI가 공식 문서에서 학습 단계(Learning Phase)를 "50 conversions per week" 기준으로 설명하는 것도 같은 맥락입니다. 관측치가 부족하면 어떤 판정도 불안정합니다.
가상 시나리오로 확인해봅시다. 제품의 Target CPA가 ₩20,000이고, 일예산 300만 원 캠페인에서 16개 소재가 돌아간다고 합시다.
- 소재 A가 3일 동안 ₩30,000만 받았다면 기대 구매는 ₩30,000 ÷ ₩20,000 = 1.5회. Poisson 분포에서 "운 나빠 0회 관측" 확률 = exp(−1.5) ≈ 22%. 즉 정상 소재도 5번에 한 번은 0회 관측됩니다. 끄는 게 오히려 오판.
- 소재 B가 3일 동안 ₩400,000을 받았다면 기대 구매는 20회. "0회 관측" 확률 = exp(−20) ≈ 0.0000002%. 이건 끄는 게 맞습니다.
같은 "3일 무전환"이지만 전혀 다른 신호입니다. 시간 단위 규칙은 캠페인 내 소재별 예산 편차를 무시하기 때문에 판정이 흔들립니다.
결함 2. "일예산 5%" 기준은 캠페인 크기 의존적이다
일예산 300만 원의 5%는 ₩150,000. 일예산 1,000만 원의 5%는 ₩500,000. 같은 "5%"지만 통계적 의미가 3배 차이 납니다. 캠페인이 스케일업할수록 판정이 느슨해지는 역설이 생깁니다.
결함 3. OFF는 이진 결정이 아니다
가장 심각한 결함입니다. 직접 구매 전환은 못 따오지만 리타겟팅 풀(retargeting pool)을 채우는 upper-funnel(어퍼퍼널, 상단 깔때기) 소재를 CPA만 보고 끄면, 특정 ad set이나 하위 퍼널 소재의 CVR이 흔들리면서 캠페인 blended ROAS가 눈에 띄게 떨어지는 케이스가 반복적으로 관찰됩니다. 운영자 커뮤니티에서는 이걸 "creative ecosystem effect(크리에이티브 생태계 효과)" 또는 "funnel cannibalization in reverse(역방향 퍼널 잠식)"라고 부릅니다.
왜 이런 일이 생기는가 — Lattice + Andromeda 아키텍처
솔직히 말하면 이건 메타가 공식 문서로 인정한 알고리즘이 아닙니다. 2024~2025년 Andromeda(ad retrieval 엔진)와 Lattice(unified ad ranking 아키텍처)가 공개된 이후 에이전시·운영자 사이에서 축적된 경험칙에 가깝습니다. 다만 아키텍처상 개연성은 충분합니다.
- Lattice: 캠페인별·surface(Feed/Reels/Stories)별로 분리되어 있던 모델을 단일 generalist model로 통합한 구조. 즉 한 소재의 성과·노출 데이터가 다른 소재의 ranking에도 영향을 줍니다 (Meta 공식 발표).
- Andromeda: 수백만 개 광고 풀에서 개인화된 후보군을 retrieval할 때 creative embedding의 다양성(creative diversity)이 핵심 시그널 (Engineering at Meta).
현장에서 관찰된 메커니즘은 네 가지로 정리할 수 있습니다.
- Audience seeding 역할: Upper-funnel 소재가 lookalike·핵심 타겟 확장의 학습을 넓게 피드하기 때문에, 이게 꺼지면 하위 퍼널이 도달할 수 있는 "warm pool"이 축소된다.
- Attribution spillover: View-through나 multi-touch 기여가 upper-funnel에서 발생하는데, 이게 사라지면 lower-funnel의 표면 CVR은 오르지만 신규 유입이 말라 전체 볼륨이 감소. (이건 엄밀히는 알고리즘이 아니라 측정 이슈.)
- Creative diversity penalty: Andromeda retrieval 단계에서 다양성이 부족하면 auction 경쟁력이 떨어진다는 관찰.
- Learning phase 재진입: 소재 구조를 급격히 바꾸면 학습 단계로 되돌아가 전체 delivery가 일시 불안정.
이 중 (1)과 (3)은 Lattice/Andromeda 구조상 개연성이 높습니다. (2)는 측정 모델링 이슈에 가깝고, (4)는 메타 공식 문서가 직접 설명합니다(Significant Edits).
솔직한 스케일 감: "계정 전체가 무너진다"는 표현은 대개 과장입니다. 실제로는 특정 ad set이나 특정 KPI(신규 유입 CVR, CPM 변동 등)가 흔들리는 수준이 대부분이고, 진짜 붕괴는 budget structure·CBO 설정 같은 다른 변수가 겹칠 때 발생합니다. 그래도 Kill 우선순위를 direct-response → upper-funnel 순으로 두는 것은 저비용 안전장치로 그 값어치가 있습니다.
메타 공식 문서 자체도 "개별 광고의 CPA만 보고 판단하지 말고 incrementality test(성과 증분 테스트)로 검증하라"고 권합니다(참고).
3. 모든 임계값은 Target CPA에서 역산한다
프레임워크의 출발점은 단 한 숫자, Target CPA(목표 전환당 비용)입니다. 제품의 손익분기점(BEP, Break-even Point)과 LTV(Lifetime Value, 고객 생애 가치)에서 역산한 "한 건의 전환당 최대 허용 비용"입니다.
가상 제품: 최종 판매가 ₩25,000, 마진 20%, LTV가 재구매 없이 단일 구매에 가까우면:
| 상수 | 값 | 근거 |
|---|---|---|
TARGET_CPA |
₩20,000 | BEP |
LTV_CAP_CPA |
₩25,000 | LTV 상한 |
SCALE_CPA |
₩16,000 | 20% 여유 소재만 스케일 대상 |
TARGET_ROAS |
1.0 | BEP ROAS |
SCALE_ROAS |
1.25 | 20% 수익 |
숫자 자체는 제품마다 다릅니다. 중요한 것은 "왜 이 숫자인가"가 economics에서 나와야 한다는 점입니다. "업계 평균 ROAS 100%"는 검증 불가능한 수식어고, "우리 BEP에서 역산한 CPA ₩20,000"은 틀리면 교정 가능한 주장입니다.
4. Kill Switch — 자본 노출량 기반 세 줄 규칙
Target CPA가 정해지면, 첫 번째 레이어(L1)는 단순한 Kill Switch입니다.
| 조건 (모두 AND) | 조치 |
|---|---|
| 누적 지출 ≥ 3×TARGET_CPA (₩60k) AND 구매 = 0 | OFF |
| 누적 지출 ≥ 5×TARGET_CPA (₩100k) AND 실제 CPA > 2×TARGET_CPA | OFF |
| 누적 지출 ≥ 5×TARGET_CPA AND ROAS < 0.40 | OFF |
시간 기반 조건은 하나도 없습니다. 오직 그 소재가 얼마나 돈을 태웠는지(자본 노출량, capital exposure)와 무엇을 돌려줬는지만 봅니다. 소재가 작은 예산을 받으면 Kill Switch에 걸리는 데 오래 걸리고, 큰 예산을 받으면 빨리 걸립니다. 소재 크기와 무관하게 공정한 판정이 됩니다.
Poisson 오탐률로 본 안전성
Target CPA ₩20k를 맞추는 정상 소재가 실수로 OFF될 확률(오탐률)을 각 규칙별로 계산:
| 규칙 | 오탐률(정상 CPA ₩20k) | 탐지율(2배 부진 CPA ₩40k) |
|---|---|---|
| 지출 ₩60k & 0구매 | 5.0% | 22.3% |
| 지출 ₩100k & ≤1구매 | 4.0% | 28.7% |
| 지출 ₩200k & ≤2구매 | 0.3% | 12.5% |
단일 체크포인트 탐지율이 22%라도, 주 2회 반복 적용 시 8주 누적 탐지율 ≈ 1 − (1−0.22)⁸ ≈ 86%. 오탐을 낮게 유지하면서 반복 체크로 탐지율을 확보하는 구조입니다.
5. 지출 × 구매 룩업표 — 주 2회 리뷰용
두 번째 레이어(L2)는 수식을 뺀 룩업표(lookup table)입니다. 수학은 스크립트가 처리하고, 사람은 표 위치만 찾습니다.
| 누적 지출 | 구매 0회 | 1회 | 2회 | 3~4회 | 5회+ |
|---|---|---|---|---|---|
| < ₩40k | Pending | Pending | Pending | 관찰 | 관찰 |
| ₩40k ~ ₩60k | Pending | 관찰 | 유지 | 유지 | 유지 |
| ₩60k ~ ₩100k | OFF | 관찰 | 유지 | 유지 | 스케일 후보 |
| ₩100k ~ ₩200k | OFF | OFF | 관찰 | 유지 | 스케일 후보 |
| ₩200k ~ ₩400k | OFF | OFF | OFF | 관찰 | 유지 |
| ₩400k+ | OFF | OFF | OFF | OFF | CPA 2배 초과 시 OFF |
"구매 한 건, 지출 ₩35,000"이 운이 나쁜 것인지 망한 것인지 매니저가 직관으로 판단하는 건 어렵지만, 표 위치 찾기는 인턴도 이사도 같은 결론이 나옵니다. 의사결정의 재현성 확보.
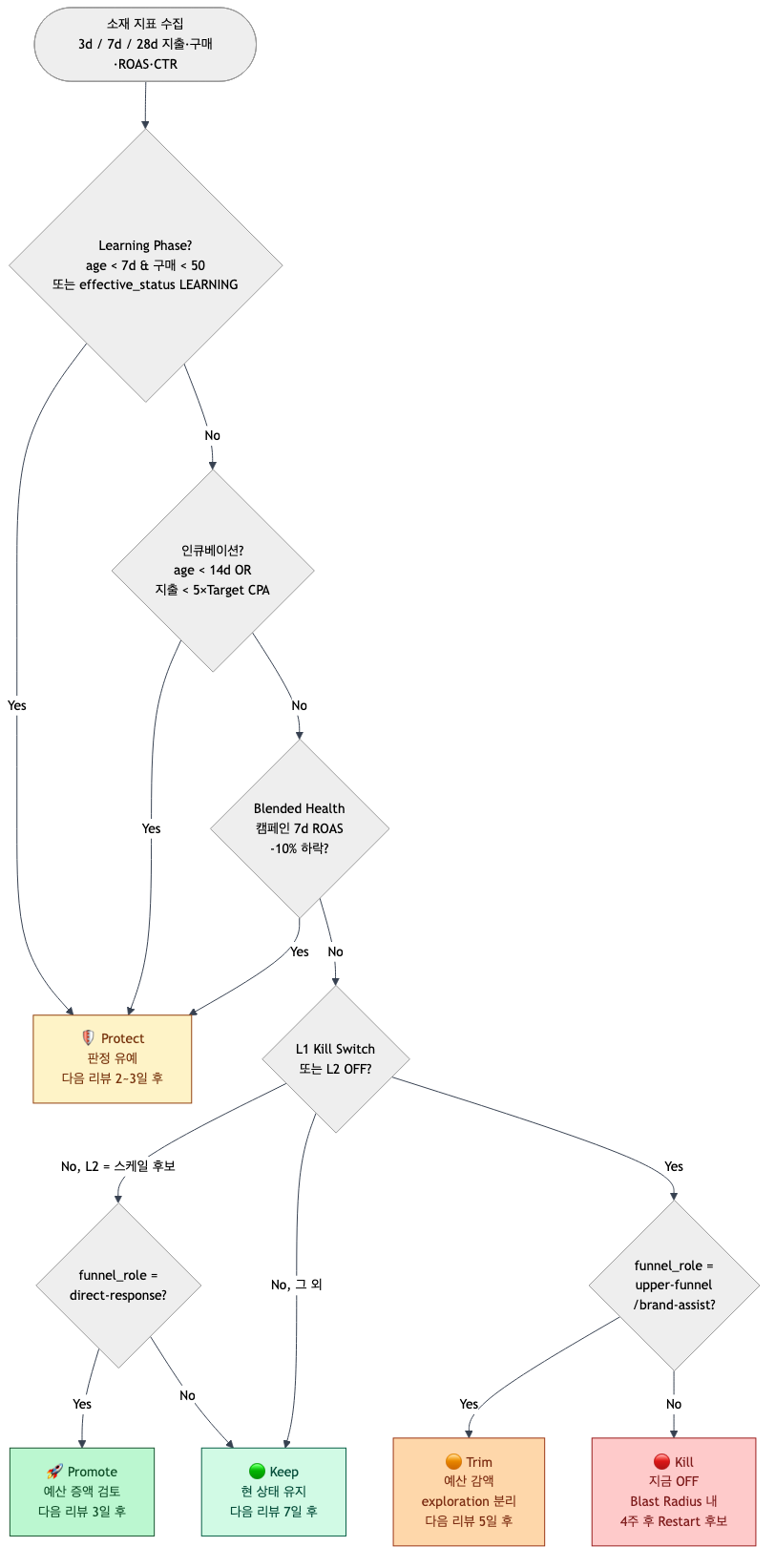
6. Kill / Trim / Protect / Promote — 5-state 라이프사이클
여기가 핵심입니다. L1(Kill Switch)·L2(룩업표)가 "OFF"라고 판정한 소재라도 실제 액션은 네 가지로 갈라집니다. 한 가지가 더 있어서 총 다섯 가지 상태.
| 상태 | 영문 | 의미 | 트리거 | 다음 리뷰 |
|---|---|---|---|---|
| 🔴 종료 | Kill | 지금 바로 OFF | (L1/L2 OFF) AND direct-response/unknown AND 계정 건강 안정 | 4주 후 Restart 후보 |
| 🟠 감액 | Trim | 예산 줄이고 exploration 풀로 이관 | (L1/L2 OFF) AND upper-funnel/brand-assist | 5일 |
| 🛡 보호 | Protect | 판정 유예 | Learning 중 / 인큐베이션 / blended 하락 | 2~3일 |
| 🚀 승격 | Promote | 예산 증액 검토 | 스케일 후보 AND direct-response | 3일 |
| 🟢 유지 | Keep | 현 상태 유지 | 그 외 | 7일 |
Funnel Role 자동 분류 — 소재를 "어떤 역할"로 볼 것인가
단순 ROAS로 Kill을 결정하기 전에 소재의 퍼널 역할을 먼저 분류합니다. 세 가지 지표를 계산:
- 구매 기여(purchase share) = 이 소재의 구매 수 / 전체 캠페인 구매 수
- Add to Cart 기여(ATC share, 장바구니 담기 기여) = 이 소재의 ATC / 전체
- View Content 기여(VC share, 콘텐츠 조회 기여) = 이 소재의 VC / 전체
- View-through 비율(VT ratio, 조회 후 전환 비율) = View-through ROAS / Click-through ROAS
분류 규칙:
- 🎯 direct-response(직접 반응): 구매 기여 ≥ 1% — Kill 1순위
- 🛡 upper-funnel(어퍼퍼널, 상단 깔때기): 구매 기여 < 1% AND (ATC 또는 VC 기여 ≥ 15%) — 리타겟팅 풀 공급 역할, Kill 후순위
- 🤝 brand-assist(브랜드 어시스트): VT ROAS ≥ 2× CT ROAS — View-through로 기여하는 자산형 소재
- ❓ unknown: 데이터 부족
직접 구매는 없지만 VC·ATC 같은 upper-funnel 이벤트를 계정에 15% 이상 공급하는 소재는 feeder(피더, 신규 유입 공급 소재) 역할입니다. CPA만 보고 이걸 끄면 §2의 creative ecosystem effect 리스크가 올라갑니다. 완전 Kill 대신 Trim(예산 감액)이 기본값인 이유입니다. RevenueCat의 BAU vs Testing 프레임워크도 이걸 전제로 설계되어 있습니다.
학습 단계(Learning Phase) 자동 보호
메타는 공식 문서에서 ad set이 significant edit(중요 변경) 이후 약 1주 내 50 results까지 도달해야 학습이 안정화된다고 명시합니다(링크). 이 기간에 CPA만 보고 끄는 것은 판정이 아니라 학습 경로 차단입니다.
자동 감지 규칙 — 둘 중 하나라도 만족하면 무조건 Protect로 올립니다:
effective_status = LEARNING또는LEARNING_LIMITED- 소재 생성/수정 후 7일 이내 AND 7일 구매 < 50
2024년까지의 학습 단계가 "기다림"에 가까웠다면, 2025년 Andromeda(안드로메다, 메타의 새 추론 엔진) 환경에서는 "적극적 교육" 성격으로 바뀌었습니다. 의미론적 다양성(Semantic Diversity)을 가진 소재를 학습 초기에 충분히 공급하는 것이 중요해졌고, 자동 Protect는 이 권고와 일치합니다.
Blended Health Safety Net — 계정 전체 건강 지표
매일 판정 직전에 캠페인 전체 7일 ROAS vs 직전 7일 ROAS를 비교합니다. 10% 이상 하락이면 "declining" 플래그를 세우고, 그 날은 모든 Kill 후보를 Protect로 다운그레이드합니다.
이유는 단순합니다. 캠페인 전체 지표가 흔들리는 중에 소재를 더 빼면 퍼널이 한 번 더 흔들릴 위험이 커집니다. 원인 분석이 먼저지 소재 OFF가 먼저가 아닙니다.
7. 크리에이티브 피로도(Creative Fatigue) 조기 탐지
Frequency(빈도) 4 이상을 단독 컷 기준으로 쓰는 건 문제가 있습니다. 캠페인 누적 Frequency는 소재 수명이 길수록 자연스럽게 올라갑니다. 그래서 피로도는 캠페인 전체가 아니라 개별 소재 기준으로 봐야 하고, Frequency 하나가 아닌 네 가지 신호를 조합해서 판단합니다.
| 신호 | 임계값 | 평문 해석 |
|---|---|---|
| 최근 3일 CTR vs 초기 3일 CTR | 25% 이상 하락 | "처음엔 잘 눌리던 게 안 눌림" |
| 주간 Frequency 증가 속도 | 주당 +0.5 이상 | "같은 사람에게 반복 노출 가속" |
| CPM(1,000회 노출 단가) | 30% 이상 상승 | "노출 단가가 비싸짐" |
| 소재 개별 Frequency | 3.0 초과 | 캠페인 전체가 아닌 개별 |
2개 이상 동시 발생 → Refresh(리뉴얼) flag. 즉시 OFF가 아니라 다음 제작 브리프에 "리뉴얼 버전 제작" 항목으로 추가합니다. 피로도는 "조금 쉬었다가 리뉴얼 버전으로 재등판"이 맞는 대응입니다.
8. Blast Radius & Guard Mode — 한꺼번에 많이 끄면 안 되는 이유
라이프사이클이 Kill로 분류한 소재가 10개라고 해서 하루에 10개를 다 끄면 안 됩니다. Meta AI는 소재가 갑자기 사라지면 예산을 급하게 재분배합니다. 재분배 과정에서 학습이 흔들립니다.
Blast Radius 규칙
- 하루 Kill 상한 = 활성 소재 수 × 20%
- 활성 16개면 하루 최대 3건
- 지난 3일 이미 Kill한 수도 합산
- Kill 우선순위: direct-response → unknown → brand-assist → upper-funnel
- 같은 role 내에선 누적 지출 큰 것부터 (출혈 큰 것 우선)
- 한도 초과분은 "Deferred" 섹션으로 이월, 내일 재평가
Guard Mode — Kill 후 7일 모니터링
Kill을 실행한 직후부터 남은 활성 소재의 가중평균 CTR과 blended ROAS를 7일간 추적합니다.
- 가중평균 CTR이 baseline 대비 −15% 이상 하락, 또는
- blended ROAS가 −10% 이상 하락
→ 즉시 경고. 어제 Kill한 소재 중 upper-funnel/brand-assist 후보를 rollback 검토. 원인 분석 전까지 추가 Kill 중단. 이게 incrementality(증분성) 측정이 없는 환경에서 할 수 있는 최소한의 대체 안전장치입니다.
9. 수동 6-step 결정 트리 — Kill 실행 직전 체크
자동 규칙을 모두 통과해도, 실제로 Kill을 실행하기 직전에 매니저가 여섯 줄 체크리스트를 읽습니다. 하나라도 "Yes"면 상위 state로 이동합니다.
- ☐ 최근 7일 내 significant edit(중요 변경) / 신규 소재 추가 / 큰 budget 변경이 있었나? → Protect (학습 안정 대기)
- ☐ 유사 ad set·유사 audience로 구조가 분산되어 있나? → 구조 단순화 후 재평가
- ☐ 이 소재를 끄면 blended CPA·total purchases·retargeting pool·new customer rate가 나빠질 징후가 있나? → Protect 또는 Trim
- ☐ 최종 CPA만 나쁘고 CTR·Hook Rate·ThruPlay만 좋나? → Kill 후보 확정 (vanity metric)
- ☐ 대체 winner 또는 비슷한 angle이 있나? → Kill 또는 강한 Trim. 없으면 제한 예산으로 Explore 유지
- ☐ 실험 풀에서 downstream 보조 신호·scale 가능성이 확인되나? → Promote
자동 판정과 사람 판단을 직렬로 묶는 게 중요합니다. 알고리즘 세계에서 사람의 눈이 마지막 안전장치입니다.
10. BAU vs Exploration — 승자 풀과 탐색 풀 분리
현장에서 가장 흔한 실수는 winner 소재와 신규 테스트 소재를 같은 캠페인에 섞어두는 것입니다. 이 구조에서는 Meta AI가 CBO(Campaign Budget Optimization, 캠페인 예산 최적화) 환경에서 최근 성과가 좋은 한두 개 소재에 예산을 몰아주고, 신규 테스트 소재는 지출을 거의 못 받거나 받자마자 cold-start 성과로 죽어버립니다.
해결책은 두 풀을 분리하는 것입니다.
- BAU(Business As Usual) 풀: 검증된 winner만 두고 예산 70~80% 집중
- Testing 풀: 신규 소재 3~5개씩 병렬 테스트. 별도 예산 20~30% 할당
RevenueCat 프레임워크에서는 Testing 풀의 승격 기준을 10,000 impressions 이상 AND 최근 2일간 baseline CPT(cost per trial, 무료 체험 전환 비용) 이하로 정의합니다. 이 기준을 만족한 소재만 BAU로 승격하고, BAU의 한 자리를 내줍니다.
Big Swing Testing — 크게 흔드는 테스트
RevenueCat의 2025 가이드는 "small A/B test의 함정"을 지적합니다. 헤드라인 한 줄만 바꾼 variation 10개를 돌리면, 결과는 대부분 유의미하지 않게 나오고 시간만 흘러갑니다. 권고는:
- Big swing test: 포맷·앵글·톤 수준에서 크게 다른 3~5개만 병렬
- 포맷(format)을 먼저 정하고 그 안에서 variation (정적 이미지 vs 15초 UGC 영상 vs 캐러셀 vs 텍스트 벽)
- Placement(피드 vs 릴스 vs 스토리) 별로 ad set을 분리해서 각 플레이스먼트에 맞는 소재만 돌리기
Placement Matching — 피드 vs 릴스의 성질 차이
흔한 오해: "Instagram Reels가 CPM 싸고 노출 많으니 효율 좋다". 실제로는 릴스 오디언스는 젊고 intent가 낮아 trial-to-subscription 전환율이 낮습니다. 반대로 Facebook Feed는 CPM이 비싸도 intent 높은 오디언스라 최종 구매 전환율이 더 나올 수 있습니다. RevenueCat 가이드는 "You'll be surprised how often Facebook is more profitable than Instagram"이라고 썼습니다.
즉 Placement matching(플레이스먼트와 소재 성격 매칭)이 중요합니다. "Reels 먼저 돌리고 안 되면 Feed"가 아니라, 소재 목적에 따라 플레이스먼트를 먼저 선택하는 구조.
11. 3층 게이트 — 규칙 변경을 검증하는 방법
"이 프레임워크가 기존 방식보다 낫다고 어떻게 증명하나요?"
이 질문에 "경험적으로", "업계 best practice", "일반적으로 이렇습니다" 같은 답으로 넘어가면 나중에 반드시 후회합니다. 대규모 규칙 변경에는 3층 게이트 스택으로 검증합니다.
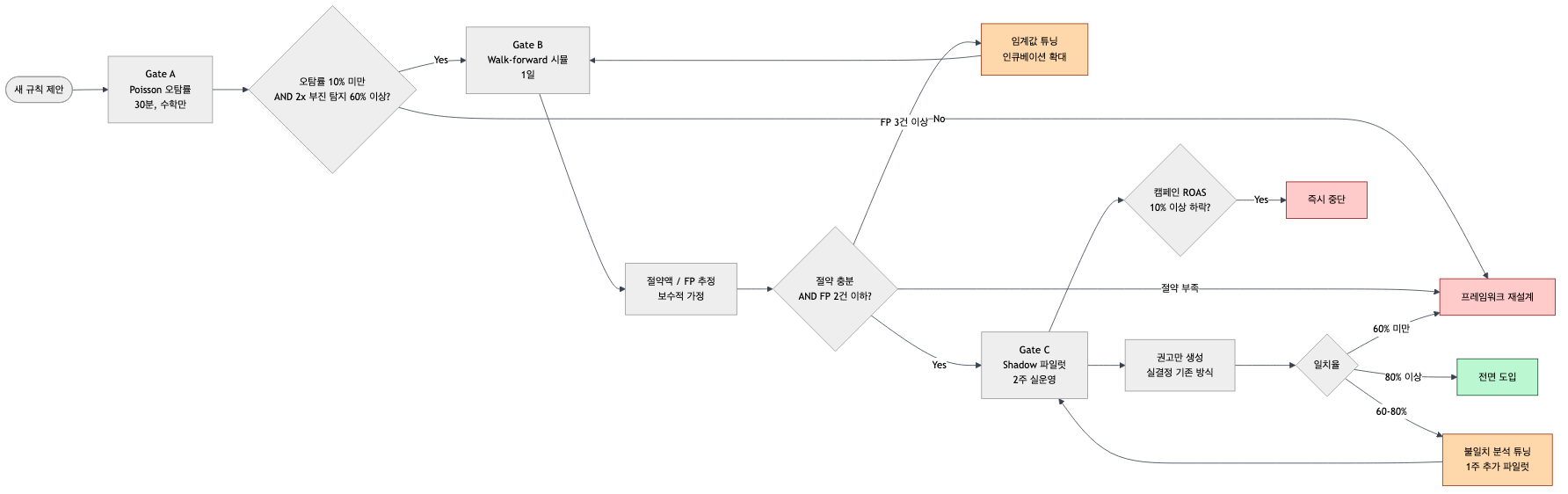
게이트 A — Poisson 오탐률 수학 점검 (30분)
각 규칙의 오탐률을 계산. 위에서 본 표 그대로입니다.
통과 조건: 평균 오탐률 < 10% AND 2배 부진 소재의 주 2회 적용 탐지율 > 60%
게이트 B — Walk-forward 시뮬레이션 (1일)
캠페인 시작일부터 현재까지의 주간 소재 데이터를 Meta Graph API로 수집. 각 날짜 t마다 t−1까지의 누적 지표로 새 규칙 적용 → OFF 결정 로그 → 이후 실제 성과와 대조.
- 절약 추정 = Σ(우리 OFF 시점 ~ 실제 OFF 시점의 지출) × ROAS 부족분
- False positive = 우리가 OFF했는데 이후 ROAS ≥ 1.0으로 회복한 건수
- 보수적 가정: Meta의 예산 재분배 없이 그대로 돌았다고 가정 (실제 절약은 이보다 큼)
통과 조건: 합리적 절약액 AND False positive ≤ 2건. 3건 이상이면 인큐베이션 창을 넓히는 방향으로 규칙 튜닝.
게이트 C — Shadow-mode 파일럿 (실운영 2주)
A·B 통과 후에도 전면 도입은 금물. 2주 동안 스크립트는 권고 리포트만 생성하고, 운영자는 기존 방식 그대로 실결정. 2주 후 일치율 평가:
- ≥ 80% → 전면 도입
- 60 ~ 80% → 불일치 5건 분석, 임계값 재튜닝, 1주 추가 파일럿
- < 60% → 프레임워크 재설계
안전 장치: 파일럿 중 캠페인 주간 ROAS가 baseline 대비 −10% 이하로 떨어지면 즉시 중단.
이 3층을 통과하지 못한 규칙은 전면 적용하지 않습니다. 피봇은 한 번에 한 층씩 리스크를 줄여가며 해야 합니다.
12. 바로 적용할 수 있는 5주 체크리스트
1주차 — 숫자 정리
- ☐ 제품의 BEP CPA, LTV, Target ROAS를 economics에서 역산
- ☐ 현재 캠페인의 7일 ROAS·CPA·Frequency·활성 소재 수 기록 (baseline)
- ☐ 소재 네이밍 규칙 정립 (YYMMDD-prefix-handle 같은 패턴)
- ☐ 소재별 funnel_role 태깅 (direct-response / upper-funnel / brand-assist / unknown)
2주차 — 게이트 A + B
- ☐ 현재 휴리스틱의 Poisson 오탐률 계산
- ☐ 과거 4~6개월 캠페인 데이터로 walk-forward 시뮬 (Meta Graph API
time_increment) - ☐ 예상 절약액·False positive 건수 확인 → 인큐베이션 창 튜닝
3주 + 4주차 — 게이트 C (Shadow pilot)
- ☐ 자동 triage 리포트 매일 생성. 실결정은 기존 방식 유지
- ☐ 매일 권고 vs 실결정 일치율 기록
- ☐ 캠페인 주간 ROAS를 baseline과 비교 모니터링
5주차 이후 — 전면 도입 + 월별 튜닝
- ☐ 일치율 80%+면 자동 triage를 운영 표준으로 전환
- ☐ 월 1회 Target CPA·LTV 재확인, 임계값 튜닝
- ☐ 분기별로 게이트 B를 자체 데이터로 재실행 → 규칙 드리프트 점검
- ☐ BAU vs Testing 풀 분리 검토 (v1.3 효과 검증 후 구조 피봇)
마치며 — 규칙은 계산되고, 검증되고, 감시되어야 한다
알고리즘 광고 환경에서 소재 의사결정은 세 가지 성질을 동시에 가져야 합니다.
- 계산 가능(Calculable): 임계값이 economics에서 역산되고, 오탐률이 수학적으로 추산된다
- 검증 가능(Verifiable): 규칙이 과거 데이터에 적용됐을 때 얼마를 절약했을지 숫자로 나온다
- 감시 가능(Observable): 적용 이후 계정 건강 지표를 실시간 추적하며 rollback 경로를 남긴다
이 세 가지를 모두 갖춘 프레임워크는 감(感)에 의존하지 않고 팀에 이식 가능한 시스템이 됩니다. 오늘 인턴이 돌려도, 내일 새 매니저가 돌려도 같은 결론이 나오는 구조입니다.
가장 반복적으로 확인한 원칙은 이것입니다.
"끄면 계정이 좋아진다"와 "끄면 계정이 무너진다"의 차이는 소재 자체보다도 학습 상태, 구조 분산, incrementality 측정 부재에서 오는 경우가 많다.
그래서 개별 ad 하나의 CPA만 보고 결론내리기보다, blended result와 holdout 성격의 incrementality 검증을 함께 봐야 합니다.
참고 자료
Meta 공식 문서
- About the Learning Phase (머신 러닝 단계 정보)
- Significant Edits and Learning Phase
- Best Practices for Ads Delivery
- Audience Fragmentation
- About Incrementality Tests
메타 아키텍처 (Lattice / Andromeda)
- Engineering at Meta: Andromeda — Next-Gen Personalized Ads Retrieval — retrieval 엔진의 creative embedding 다양성 설명
- Meta Business: AI Innovation in Meta's Ads Ranking (Lattice) — surface·objective 통합 generalist model
프레임워크·사례
- RevenueCat: High-Velocity Creative Testing Framework — BAU vs Testing 분리, ICE score, 10K impressions baseline
- RevenueCat: Meta Ads in 2025 — AEM, Big swing testing, Placement matching, UGC evolution
- Jon Loomer: Effective Meta Advertising Metrics — secondary vs desired action metrics
- Motion Agency / Common Thread Collective / Foxwell Digital — creative diversity 기반 Meta Ads 운영 케이스 스터디를 자주 공개하는 해외 에이전시 (검색: "[에이전시명] creative diversity Meta")
📞 퍼포먼스 마케팅 컨설팅
메타 광고 소재 의사결정을 시스템으로 만들고 싶다면:
🎁 오픈소스 템플릿 — meta-ads-triage-template
이 글에서 소개한 Kill/Trim/Protect/Promote 라이프사이클을 구현한 Node.js 스크립트 템플릿을 MIT 라이선스로 공개했습니다. 일일 triage 리포트 생성, 태그별 성과 피벗, walk-forward 백테스트 전부 포함.
github.com/retention-corp/meta-ads-triage-template →
.env에 Meta Graph API 토큰과 캠페인 ID만 넣으면 바로 실행 가능합니다. scripts/lib/rules.mjs의 ECONOMICS 상수를 본인 제품의 Target CPA로 수정하는 것이 유일한 필수 커스터마이즈 단계입니다.
뉴스레터 구독 → (주간 퍼포먼스 마케팅·그로스 인사이트)